This really is the ace in the hole for Microsoft. They are closing the gap between console and master race. Scorpio is going to kick ass, and be the next evolution in the console game. Expect the Halo series to experience a rebirth with Halo 6. Cross-platform will introduce the game to a whole new demographic of master race players. All this is possible, because the Scorpio is the real deal. Large and in charge. Size matters, and Scorpio is packing heat.
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
Your PC built in 2014/2015 is missing double rate 'float16' feature.
Vega 11 with 6 TFLOPS float32 yields 12 TFLOPS float16.
Well I cant comment on Scorpio as I don't really know much that is concrete about it. But for MS, cross support between PC and Xbox is a no brainer. Th great majority and not like 55%, we're talking Monopoly levels, of PCs use MS' Windows OS. Obviously they want to support that product and will their Xbox. Seems obvious.
@ronvalencia: Yeah cause 16 bit floating point is going to make all the difference.
GeForce FX's float16 shaders path has existed before DX10's float32 hardware changes.
Tegra X1 and GP100 has double rate float16 shaders. GP102 and GP104 has broken float16 shaders i.e. 1/64 speed of float32 rate which is exposed by CUDA 7.5. Float32 units can emulate float16 without any performance benefits.
VooFoo Dev Was Initially Doubtful About PS4 PRO GPU’s Capabilities But Was Pleasantly Surprised Later
“I was actually very pleasantly surprised. Not initially – the specs on paper don’t sound great, as you are trying to fill four times as many pixels on screen with a GPU that is only just over twice as powerful, and without a particularly big increase in memory bandwidth,” he explained, echoing the sentiment that a lot of us seem to have, before adding, “But when you drill down into the detail, the PS4 Pro GPU has a lot of new features packed into it too, which means you can do far more per cycle than you can with the original GPU (twice as much in fact, in some cases). You’ve still got to work very hard to utilise the extra potential power, but we were very keen to make this happen in Mantis Burn Racing.
“In Mantis Burn Racing, much of the graphical complexity is in the pixel detail, which means most of our cycles are spent doing pixel shader work. Much of that is work that can be done at 16-bit rather than 32-bit precision, without any perceivable difference in the end result – and PS4 Pro can do 16 bit-floating point operations twice as fast as the 32-bit equivalent.”
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
FP16 optimisation is similar to GeForce FX's era The Way Meant to be Played optimisation paths.
On the original PS4, developers already using FP16 for raster hardware e.g. Kill Zone ShadowFall.
Sebbbi a dev on Beyond3D had this to say about FP16
Sebbbi (A dev on Beyond3D) comment on FP16.
Originally Posted by Sebbbi on Beyond3D 2 years ago
Sometimes it requires more work to get lower precision calculations to work (with zero image quality degradation), but so far I haven't encountered big problems in fitting my pixel shader code to FP16 (including lighting code). Console developers have a lot of FP16 pixel shader experience because of PS3. Basically all PS3 pixel shader code was running on FP16.
It is still is very important to pack the data in memory as tightly as possible as there is never enough bandwidth to lose. For example 16 bit (model space) vertex coordinates are still commonly used, the material textures are still dxt compressed (barely 8 bit quality) and the new HDR texture formats (BC6H) commonly used in cube maps have significantly less precision than a 16 bit float. All of these can be processed by 16 bit ALUs in pixel shader with no major issues. The end result will still be eventually stored to 8 bit per channel back buffer and displayed.
Could you give us some examples of operations done in pixel shaders that require higher than 16 bit float processing?
EDIT: One example where 16 bit float processing is not enough: Exponential variance shadow mapping (EVSM) needs both 32 bit storage (32 bit float textures + 32 bit float filtering) and 32 bit float ALU processing.
However EVSM is not yet universally possible on mobile platforms right now, as there's no standard support for 32 bit float filtering in mobile devices (OpenGL ES 3.0 just recently added support for 16 bit float filtering, 32 bit float filtering is not yet present). Obviously GPU manufacturers can have OpenGL ES extensions to add FP32 filtering support if their GPU supports it (as most GPUs should as this has been a required feature in DirectX since 10.0).
#33sebbbi, Oct 18, 2014 Last edited by a moderator: Oct 18, 2014
What do you think of Sony’s PlayStation 4 Pro in terms of performance? Is it powerful enough to deliver 4K gaming?
PS4Pro is a great upgrade over base PS4. the CPU didn’t get a big upgrade, but GPU is a beast. It also has some interesting hardware features, which help with achieving 4K resolution without resorting to brute force.
PS4 Pro’s architect Mark Cerny said that the console introduces the ability to perform two 16-bit operations at the same time, instead of one 32-bit operation. He suggested that this has the potential to “radically increase the performance of games” – do you agree with this assessment?
Yes. Half precision (16 bit) instructions are a great feature. They were used some time ago in Geforce FX, but didn’t manage to gain popularity and were dropped. It’s a pity, because most operations don’t need full float (32 bit) precision and it’s a waste to use full float precision for them. With half precision instructions we could gain much better performance without sacrificing image quality.
MS , AMD , Sony & Intel think it will work for graphics
GCN 3 /4 has single rate native float 16 which reduces memory bandwidth usage i.e. on memory bandwidth bound situations, native float16 shaders support can double the effective floating point operations within the same memory bandwidth. A double rate float16 occurs at the GPU level.
With SM6's native float16, AMD is going to do another Async compute like gimping on exiting NVIDIA GPUs.
AMD is using their relationship with MS to drive SM6's direction.
As far as console players getting tired of playing against PC players it's a non issue. In its current state they don't allow ranked competitive modes to crossplay. I imagine they will when Scorpio gets keyboard and mouse support then again it's a non issue.
Whose alt are we dealing with this time? Is that you again Nyad? Okay I'll play along with this nonsense. What is the advantage exactly OP? Have you just found a new buzzword (cross-platform) and you don't know what it means but it sounds good so you're going to bleat about it?
As has been explained, console gamers v PC gamers will get completely ruined and won't come back for a second humiliation.
It's like this 'play anywhere' crap, like Xbox players will buy a PC so they can play the same game on it or vice versa lol, just buzzwords, in the real world they mean nothing. And Scorpio will have nothing and I mean 'nothing' that you can't already play on PC or Xbox One and with very few exceptions, PS4.
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
well ,FPS is not the only genre , I played Rocket League and Gwent with Xbox players , gotta say it was really a cool experience
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
well ,FPS is not the only genre , I played Rocket League and Gwent with Xbox players , gotta say it was really a cool experience
It's Halo 6 speculation thread, which is why I mentioned the controller/mouse disparity in FPS games.
Been playing PC gamers all week on Gears 4 social versus, its pretty cool, haven't noticed much of a difference to be honest....still kicking ass. But its definitely a plus as the game has a larger population, more people get to play the game.....glad they are doing it.
@ronvalencia: Yeah cause 16 bit floating point is going to make all the difference.
GeForce FX's float16 shaders path has existed before DX10's float32 hardware changes.
Tegra X1 and GP100 has double rate float16 shaders. GP102 and GP104 has broken float16 shaders i.e. 1/64 speed of float32 rate which is exposed by CUDA 7.5. Float32 units can emulate float16 without any performance benefits.
VooFoo Dev Was Initially Doubtful About PS4 PRO GPU’s Capabilities But Was Pleasantly Surprised Later
“I was actually very pleasantly surprised. Not initially – the specs on paper don’t sound great, as you are trying to fill four times as many pixels on screen with a GPU that is only just over twice as powerful, and without a particularly big increase in memory bandwidth,” he explained, echoing the sentiment that a lot of us seem to have, before adding, “But when you drill down into the detail, the PS4 Pro GPU has a lot of new features packed into it too, which means you can do far more per cycle than you can with the original GPU (twice as much in fact, in some cases). You’ve still got to work very hard to utilise the extra potential power, but we were very keen to make this happen in Mantis Burn Racing.
“In Mantis Burn Racing, much of the graphical complexity is in the pixel detail, which means most of our cycles are spent doing pixel shader work. Much of that is work that can be done at 16-bit rather than 32-bit precision, without any perceivable difference in the end result – and PS4 Pro can do 16 bit-floating point operations twice as fast as the 32-bit equivalent.”
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
FP16 optimisation is similar to GeForce FX's era The Way Meant to be Played optimisation paths.
On the original PS4, developers already using FP16 for raster hardware e.g. Kill Zone ShadowFall.
Sebbbi a dev on Beyond3D had this to say about FP16
Sebbbi (A dev on Beyond3D) comment on FP16.
Originally Posted by Sebbbi on Beyond3D 2 years ago
Sometimes it requires more work to get lower precision calculations to work (with zero image quality degradation), but so far I haven't encountered big problems in fitting my pixel shader code to FP16 (including lighting code). Console developers have a lot of FP16 pixel shader experience because of PS3. Basically all PS3 pixel shader code was running on FP16.
It is still is very important to pack the data in memory as tightly as possible as there is never enough bandwidth to lose. For example 16 bit (model space) vertex coordinates are still commonly used, the material textures are still dxt compressed (barely 8 bit quality) and the new HDR texture formats (BC6H) commonly used in cube maps have significantly less precision than a 16 bit float. All of these can be processed by 16 bit ALUs in pixel shader with no major issues. The end result will still be eventually stored to 8 bit per channel back buffer and displayed.
Could you give us some examples of operations done in pixel shaders that require higher than 16 bit float processing?
EDIT: One example where 16 bit float processing is not enough: Exponential variance shadow mapping (EVSM) needs both 32 bit storage (32 bit float textures + 32 bit float filtering) and 32 bit float ALU processing.
However EVSM is not yet universally possible on mobile platforms right now, as there's no standard support for 32 bit float filtering in mobile devices (OpenGL ES 3.0 just recently added support for 16 bit float filtering, 32 bit float filtering is not yet present). Obviously GPU manufacturers can have OpenGL ES extensions to add FP32 filtering support if their GPU supports it (as most GPUs should as this has been a required feature in DirectX since 10.0).
#33sebbbi, Oct 18, 2014 Last edited by a moderator: Oct 18, 2014
What do you think of Sony’s PlayStation 4 Pro in terms of performance? Is it powerful enough to deliver 4K gaming?
PS4Pro is a great upgrade over base PS4. the CPU didn’t get a big upgrade, but GPU is a beast. It also has some interesting hardware features, which help with achieving 4K resolution without resorting to brute force.
PS4 Pro’s architect Mark Cerny said that the console introduces the ability to perform two 16-bit operations at the same time, instead of one 32-bit operation. He suggested that this has the potential to “radically increase the performance of games” – do you agree with this assessment?
Yes. Half precision (16 bit) instructions are a great feature. They were used some time ago in Geforce FX, but didn’t manage to gain popularity and were dropped. It’s a pity, because most operations don’t need full float (32 bit) precision and it’s a waste to use full float precision for them. With half precision instructions we could gain much better performance without sacrificing image quality.
MS , AMD , Sony & Intel think it will work for graphics
GCN 3 /4 has single rate native float 16 which reduces memory bandwidth usage i.e. on memory bandwidth bound situations, native float16 shaders support can double the effective floating point operations within the same memory bandwidth. A double rate float16 occurs at the GPU level.
With SM6's native float16, AMD is going to do another Async compute like gimping on exiting NVIDIA GPUs.
AMD is using their relationship with MS to drive SM6's direction.
Even the dude mentions in your own post you need 32 bit for some tasks, so double performance aint going to happen.
Now showcase me a game that uses fp16 that we can compare? because so far i see is that fp16 on the ps4 pro not really helping them out very much. It does exactly what you would aspect from what the console would push in the fp32 department.
6tflops on top of it, if that's amd flops isn't going to yield more then 980 gtx performance at it's absolute best. Let alone titan xp performance.
I wonder why all that magic double peformance 16 floating point performance is going into then. Should be easy performance gain then.
fp16 sounds more and more like our dx12 update, loads of hot air that results in zero performance gain. Or almost nothing.
@ronvalencia: Yeah cause 16 bit floating point is going to make all the difference.
GeForce FX's float16 shaders path has existed before DX10's float32 hardware changes.
Tegra X1 and GP100 has double rate float16 shaders. GP102 and GP104 has broken float16 shaders i.e. 1/64 speed of float32 rate which is exposed by CUDA 7.5. Float32 units can emulate float16 without any performance benefits.
VooFoo Dev Was Initially Doubtful About PS4 PRO GPU’s Capabilities But Was Pleasantly Surprised Later
“I was actually very pleasantly surprised. Not initially – the specs on paper don’t sound great, as you are trying to fill four times as many pixels on screen with a GPU that is only just over twice as powerful, and without a particularly big increase in memory bandwidth,” he explained, echoing the sentiment that a lot of us seem to have, before adding, “But when you drill down into the detail, the PS4 Pro GPU has a lot of new features packed into it too, which means you can do far more per cycle than you can with the original GPU (twice as much in fact, in some cases). You’ve still got to work very hard to utilise the extra potential power, but we were very keen to make this happen in Mantis Burn Racing.
“In Mantis Burn Racing, much of the graphical complexity is in the pixel detail, which means most of our cycles are spent doing pixel shader work. Much of that is work that can be done at 16-bit rather than 32-bit precision, without any perceivable difference in the end result – and PS4 Pro can do 16 bit-floating point operations twice as fast as the 32-bit equivalent.”
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
FP16 optimisation is similar to GeForce FX's era The Way Meant to be Played optimisation paths.
On the original PS4, developers already using FP16 for raster hardware e.g. Kill Zone ShadowFall.
Sebbbi a dev on Beyond3D had this to say about FP16
Sebbbi (A dev on Beyond3D) comment on FP16.
Originally Posted by Sebbbi on Beyond3D 2 years ago
Sometimes it requires more work to get lower precision calculations to work (with zero image quality degradation), but so far I haven't encountered big problems in fitting my pixel shader code to FP16 (including lighting code). Console developers have a lot of FP16 pixel shader experience because of PS3. Basically all PS3 pixel shader code was running on FP16.
It is still is very important to pack the data in memory as tightly as possible as there is never enough bandwidth to lose. For example 16 bit (model space) vertex coordinates are still commonly used, the material textures are still dxt compressed (barely 8 bit quality) and the new HDR texture formats (BC6H) commonly used in cube maps have significantly less precision than a 16 bit float. All of these can be processed by 16 bit ALUs in pixel shader with no major issues. The end result will still be eventually stored to 8 bit per channel back buffer and displayed.
Could you give us some examples of operations done in pixel shaders that require higher than 16 bit float processing?
EDIT: One example where 16 bit float processing is not enough: Exponential variance shadow mapping (EVSM) needs both 32 bit storage (32 bit float textures + 32 bit float filtering) and 32 bit float ALU processing.
However EVSM is not yet universally possible on mobile platforms right now, as there's no standard support for 32 bit float filtering in mobile devices (OpenGL ES 3.0 just recently added support for 16 bit float filtering, 32 bit float filtering is not yet present). Obviously GPU manufacturers can have OpenGL ES extensions to add FP32 filtering support if their GPU supports it (as most GPUs should as this has been a required feature in DirectX since 10.0).
#33sebbbi, Oct 18, 2014 Last edited by a moderator: Oct 18, 2014
What do you think of Sony’s PlayStation 4 Pro in terms of performance? Is it powerful enough to deliver 4K gaming?
PS4Pro is a great upgrade over base PS4. the CPU didn’t get a big upgrade, but GPU is a beast. It also has some interesting hardware features, which help with achieving 4K resolution without resorting to brute force.
PS4 Pro’s architect Mark Cerny said that the console introduces the ability to perform two 16-bit operations at the same time, instead of one 32-bit operation. He suggested that this has the potential to “radically increase the performance of games” – do you agree with this assessment?
Yes. Half precision (16 bit) instructions are a great feature. They were used some time ago in Geforce FX, but didn’t manage to gain popularity and were dropped. It’s a pity, because most operations don’t need full float (32 bit) precision and it’s a waste to use full float precision for them. With half precision instructions we could gain much better performance without sacrificing image quality.
MS , AMD , Sony & Intel think it will work for graphics
GCN 3 /4 has single rate native float 16 which reduces memory bandwidth usage i.e. on memory bandwidth bound situations, native float16 shaders support can double the effective floating point operations within the same memory bandwidth. A double rate float16 occurs at the GPU level.
With SM6's native float16, AMD is going to do another Async compute like gimping on exiting NVIDIA GPUs.
AMD is using their relationship with MS to drive SM6's direction.
Even the dude mentions in your own post you need 32 bit for some tasks, so double performance aint going to happen.
Now showcase me a game that uses fp16 that we can compare? because so far i see is that fp16 on the ps4 pro not really helping them out very much. It does exactly what you would aspect from what the console would push in the fp32 department.
6tflops on top of it, if that's amd flops isn't going to yield more then 980 gtx performance at it's absolute best. Let alone titan xp performance.
I wonder why all that magic double peformance 16 floating point performance is going into then. Should be easy performance gain then.
fp16 sounds more and more like our dx12 update, loads of hot air that results in zero performance gain. Or almost nothing.
Again, AMD's TFLOPS is not the problem!!!
YOU: Now showcase me a game that uses fp16 that we can compare?
Again,
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
"Console developers have a lot of FP16 pixel shader experience because of PS3.Basically all PS3 pixel shader code was running on FP16."
You can compare FLOPS only under specific conditions.
AMD's shader FLOPS are not the problem!!!!!!!!!
From https://developer.nvidia.com/dx12-dos-and-donts
On DX11 the driver does farm off asynchronous tasks to driver worker threads where possible – this doesn’t happen anymore under DX12
Nvidia DX11 driver already using key DX12 style speed up methods i.e.
1. asynchronous tasks
2. threads i.e. more than one threads
Nvidia DX11 driver has at least 1.72X the draw call headroom.
Under Vulkan and DX12, AMD GPU nullifies NVIDIA's DX11 driver advantage.
R9-Fury X's raw 8.6 TFLOPS exposed with Vulkan+Async Compute+AMD Intrinsics+No Nvidia tessellation over draw politics (it wouldn't exist on consoles).
Async Compute workloads are usually out of phase with Sync Graphics Command's memory bandwidth access.
980 Ti's 6.4 TFLOPS gap with Fury X's 8.6 TFLOPS is 1.34X
Doom Vulkan's framerate gap between 980 Ti and Fury X is 1.30X
AMD GCN hardware is fine, but the AMD DX11/OGL driver is not on par with NVidia's DX11/OGL driver.
When there's sufficient shader (FLOPS) resources, the major bottleneck is the effective memory bandwidth i.e. ALUs needs to read and write the results to memory.
This is why AMD is pushing for HBM2 and why NAVI will get a new memory design.
Async compute's memory bandwidth consumption is out of sync from Sync compute's memory bandwidth consumption
---------------
As for RX-480, any overclock editions will be bounded by effective memory bandwidth.
For reference RX-480
((((256 bit x 8000Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 263.84 GB/s
--
Scorpio's "more than 320 GB/s memory bandwidth" claim.
((((384 bit x GDDR5-6900 Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 341 .34 GB/s
PS;
((384 bit x GDDR5-6900 Mhz) / 8) / 1024) = 323 GB/s physical memory bandwidth.
((384 bit x GDDR5-7000 Mhz) / 8) / 1024) = 328 GB/s physical memory bandwidth.
Comparison.
The memory bandwidth gap between Fury X and R9-290 = 1.266X (random textures)
With Fury X, it's memory compression is inferior to NVIDIA's Maxwell.
The FLOPS gap between Fury X and R9-290 = 1.48X
The frame rate gap between R9-290X and Fury X is 1.19X.
Random texture memory bandwidth gap's 1.266X factor is closer to frame rate gap's 1.19X.FLOPS gap between R9-290X (5.8 TFLOPS)and Fury X (8.6 TFLOPS) plays very little part with frame rate gap.
With 980 Ti (5.63 TFLOPS), it's superior memory compression enables it to match Fury X's results.
Conclusion:
1. When there's enough FLOPS for a particular workload, effective memory bandwidth is better prediction method for higher grade GPUs.
2. The effective memory bandwidth between Fury X and 980 Ti are similar hence similar results.
-------------------
Example of near brain dead Xbox One ports running PC GPUs.
Frame rate difference between 980 Ti and R9-290X is 1.31X with Forza 6 Apex
Effective memory bandwidth between 980 Ti and R9-290X is 1.38X
Again, Fury X and 980 Ti has similar effective memory bandwidth, hence similar results for most cases.
Forza 6 Apex is another example for effective memory bandwidth influencing the frame rate result.
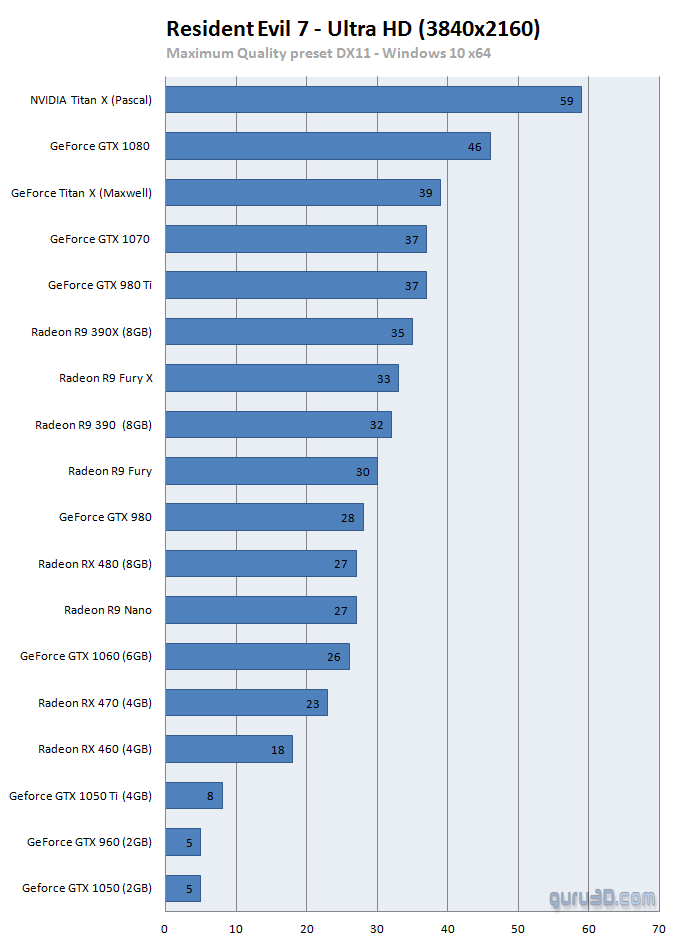
For RE7 PC build, R9-390X's 5.9 TFLOPS nears 980 Ti's 5.63 TFLOPS and 1070's 6.4 TFLOPS.
RE7's geometry load would be optimised for AMD GPUs.
Fury X's 4 GB VRAM gimps the GPU.
For AMD Vega http://www.anandtech.com/show/11002/the-amd-vega-gpu-architecture-teaser/3
ROPs & Rasterizers: Binning for the Win(ning)
We’ll suitably round-out our overview of AMD’s Vega teaser with a look at the front and back-ends of the GPU architecture. While AMD has clearly put quite a bit of effort into the shader core, shader engines, and memory, they have not ignored the rasterizers at the front-end or the ROPs at the back-end. In fact this could be one of the most important changes to the architecture from an efficiency standpoint.
Back in August, our pal David Kanter discovered one of the important ingredients of the secret sauce that is NVIDIA’s efficiency optimizations. As it turns out, NVIDIA has been doing tile based rasterization and binning since Maxwell, and that this was likely one of the big reasons Maxwell’s efficiency increased by so much. Though NVIDIA still refuses to comment on the matter, from what we can ascertain, breaking up a scene into tiles has allowed NVIDIA to keep a lot more traffic on-chip, which saves memory bandwidth, but also cuts down on very expensive accesses to VRAM.
For Vega, AMD will be doing something similar. The architecture will add support for what AMD calls the Draw Stream Binning Rasterizer, which true to its name, will give Vega the ability to bin polygons by tile. By doing so, AMD will cut down on the amount of memory accesses by working with smaller tiles that can stay-on chip. This will also allow AMD to do a better job of culling hidden pixels, keeping them from making it to the pixel shaders and consuming resources there.
As we have almost no detail on how AMD or NVIDIA are doing tiling and binning, it’s impossible to say with any degree of certainty just how close their implementations are, so I’ll refrain from any speculation on which might be better. But I’m not going to be too surprised if in the future we find out both implementations are quite similar. The important thing to take away from this right now is that AMD is following a very similar path to where we think NVIDIA captured some of their greatest efficiency gains on Maxwell, and that in turn bodes well for Vega.
Meanwhile, on the ROP side of matters, besides baking in the necessary support for the aforementioned binning technology, AMD is also making one other change to cut down on the amount of data that has to go off-chip to VRAM. AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache.
PS4 Pro's 4.2 TFLOPS GPU bottlenecked by memory bandwidth.
GeForce GTX 980 has superior delta memory compression and tile render which reduces external memory bandwidth.
The main purpose for native FP16 is to reduce memory bandwidth which is the alternative Maxwell's superior delta memory compression and tile render memory bandwidth savings, but Vega has Maxwell style tiling render.
YOU blame AMD FLOPS != NVIDIA FLOPS when the real problem is AMD's non-FLOPS hardware that gimps AMD's shader FLOPS.
IF FP16 shaders are useless for games, how come NVIDIA Volta has rumoured to have double rate FP16 feature? Would your view change when NVIDIA gains their own double rate FP16 feature for GTX 2080 or GTX 2080 Ti or Titan X Volta?
@ronvalencia: Yeah cause 16 bit floating point is going to make all the difference.
GeForce FX's float16 shaders path has existed before DX10's float32 hardware changes.
Tegra X1 and GP100 has double rate float16 shaders. GP102 and GP104 has broken float16 shaders i.e. 1/64 speed of float32 rate which is exposed by CUDA 7.5. Float32 units can emulate float16 without any performance benefits.
VooFoo Dev Was Initially Doubtful About PS4 PRO GPU’s Capabilities But Was Pleasantly Surprised Later
“I was actually very pleasantly surprised. Not initially – the specs on paper don’t sound great, as you are trying to fill four times as many pixels on screen with a GPU that is only just over twice as powerful, and without a particularly big increase in memory bandwidth,” he explained, echoing the sentiment that a lot of us seem to have, before adding, “But when you drill down into the detail, the PS4 Pro GPU has a lot of new features packed into it too, which means you can do far more per cycle than you can with the original GPU (twice as much in fact, in some cases). You’ve still got to work very hard to utilise the extra potential power, but we were very keen to make this happen in Mantis Burn Racing.
“In Mantis Burn Racing, much of the graphical complexity is in the pixel detail, which means most of our cycles are spent doing pixel shader work. Much of that is work that can be done at 16-bit rather than 32-bit precision, without any perceivable difference in the end result – and PS4 Pro can do 16 bit-floating point operations twice as fast as the 32-bit equivalent.”
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
FP16 optimisation is similar to GeForce FX's era The Way Meant to be Played optimisation paths.
On the original PS4, developers already using FP16 for raster hardware e.g. Kill Zone ShadowFall.
Sebbbi a dev on Beyond3D had this to say about FP16
Sebbbi (A dev on Beyond3D) comment on FP16.
Originally Posted by Sebbbi on Beyond3D 2 years ago
Sometimes it requires more work to get lower precision calculations to work (with zero image quality degradation), but so far I haven't encountered big problems in fitting my pixel shader code to FP16 (including lighting code). Console developers have a lot of FP16 pixel shader experience because of PS3. Basically all PS3 pixel shader code was running on FP16.
It is still is very important to pack the data in memory as tightly as possible as there is never enough bandwidth to lose. For example 16 bit (model space) vertex coordinates are still commonly used, the material textures are still dxt compressed (barely 8 bit quality) and the new HDR texture formats (BC6H) commonly used in cube maps have significantly less precision than a 16 bit float. All of these can be processed by 16 bit ALUs in pixel shader with no major issues. The end result will still be eventually stored to 8 bit per channel back buffer and displayed.
Could you give us some examples of operations done in pixel shaders that require higher than 16 bit float processing?
EDIT: One example where 16 bit float processing is not enough: Exponential variance shadow mapping (EVSM) needs both 32 bit storage (32 bit float textures + 32 bit float filtering) and 32 bit float ALU processing.
However EVSM is not yet universally possible on mobile platforms right now, as there's no standard support for 32 bit float filtering in mobile devices (OpenGL ES 3.0 just recently added support for 16 bit float filtering, 32 bit float filtering is not yet present). Obviously GPU manufacturers can have OpenGL ES extensions to add FP32 filtering support if their GPU supports it (as most GPUs should as this has been a required feature in DirectX since 10.0).
#33sebbbi, Oct 18, 2014 Last edited by a moderator: Oct 18, 2014
What do you think of Sony’s PlayStation 4 Pro in terms of performance? Is it powerful enough to deliver 4K gaming?
PS4Pro is a great upgrade over base PS4. the CPU didn’t get a big upgrade, but GPU is a beast. It also has some interesting hardware features, which help with achieving 4K resolution without resorting to brute force.
PS4 Pro’s architect Mark Cerny said that the console introduces the ability to perform two 16-bit operations at the same time, instead of one 32-bit operation. He suggested that this has the potential to “radically increase the performance of games” – do you agree with this assessment?
Yes. Half precision (16 bit) instructions are a great feature. They were used some time ago in Geforce FX, but didn’t manage to gain popularity and were dropped. It’s a pity, because most operations don’t need full float (32 bit) precision and it’s a waste to use full float precision for them. With half precision instructions we could gain much better performance without sacrificing image quality.
MS , AMD , Sony & Intel think it will work for graphics
GCN 3 /4 has single rate native float 16 which reduces memory bandwidth usage i.e. on memory bandwidth bound situations, native float16 shaders support can double the effective floating point operations within the same memory bandwidth. A double rate float16 occurs at the GPU level.
With SM6's native float16, AMD is going to do another Async compute like gimping on exiting NVIDIA GPUs.
AMD is using their relationship with MS to drive SM6's direction.
Even the dude mentions in your own post you need 32 bit for some tasks, so double performance aint going to happen.
Now showcase me a game that uses fp16 that we can compare? because so far i see is that fp16 on the ps4 pro not really helping them out very much. It does exactly what you would aspect from what the console would push in the fp32 department.
6tflops on top of it, if that's amd flops isn't going to yield more then 980 gtx performance at it's absolute best. Let alone titan xp performance.
I wonder why all that magic double peformance 16 floating point performance is going into then. Should be easy performance gain then.
fp16 sounds more and more like our dx12 update, loads of hot air that results in zero performance gain. Or almost nothing.
AMD's TFLOPS is not the problem!!!
You can compare FLOPS only under specific conditions.
From https://developer.nvidia.com/dx12-dos-and-donts
On DX11 the driver does farm off asynchronous tasks to driver worker threads where possible – this doesn’t happen anymore under DX12
Nvidia DX11 driver already using key DX12 style speed up methods i.e.
1. asynchronous tasks
2. threads i.e. more than one threads
Nvidia DX11 driver has at least 1.72X the draw call headroom.
Under Vulkan and DX12, AMD GPU nullifies NVIDIA's DX11 driver advantage.
R9-Fury X's raw 8.6 TFLOPS exposed with Vulkan+Async Compute+AMD Intrinsics+No Nvidia tessellation over draw politics (it wouldn't exist on consoles).
Async Compute workloads are usually out of phase with Sync Graphics Command's memory bandwidth access.
980 Ti's 6.4 TFLOPS gap with Fury X's 8.6 TFLOPS is 1.34X
Doom Vulkan's framerate gap between 980 Ti and Fury X is 1.30X
AMD GCN hardware is fine, but the AMD DX11/OGL driver is not on par with NVidia's DX11/OGL driver.
When there's sufficient shader (FLOPS) resources, the major bottleneck is the effective memory bandwidth i.e. ALUs needs to read and write the results to memory.
This is why AMD is pushing for HBM2 and why NAVI will get a new memory design.
Async compute's memory bandwidth consumption is out of sync from Sync compute's memory bandwidth consumption
---------------
As for RX-480, any overclock editions will be bounded by effective memory bandwidth.
For reference RX-480
((((256 bit x 8000Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 263.84 GB/s
--
Scorpio's "more than 320 GB/s memory bandwidth" claim.
((((384 bit x GDDR5-6900 Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 341 .34 GB/s
PS;
((384 bit x GDDR5-6900 Mhz) / 8) / 1024) = 323 GB/s physical memory bandwidth.
((384 bit x GDDR5-7000 Mhz) / 8) / 1024) = 328 GB/s physical memory bandwidth.
Comparison.
The memory bandwidth gap between Fury X and R9-290 = 1.266X (random textures)
With Fury X, it's memory compression is inferior to NVIDIA's Maxwell.
The FLOPS gap between Fury X and R9-290 = 1.48X
The frame rate gap between R9-290X and Fury X is 1.19X.
Random texture memory bandwidth gap's 1.266X factor is closer to frame rate gap's 1.19X.FLOPS gap between R9-290X (5.8 TFLOPS)and Fury X (8.6 TFLOPS) plays very little part with frame rate gap.
With 980 Ti (5.63 TFLOPS), it's superior memory compression enables it to match Fury X's results.
Conclusion:
1. When there's enough FLOPS for a particular workload, effective memory bandwidth is better prediction method for higher grade GPUs.
2. The effective memory bandwidth between Fury X and 980 Ti are similar hence similar results.
-------------------
Example of near brain dead Xbox One ports running PC GPUs.
Frame rate difference between 980 Ti and R9-290X is 1.31X with Forza 6 Apex
Effective memory bandwidth between 980 Ti and R9-290X is 1.38X
Forza 6 Apex is another example for effective memory bandwidth influencing the frame rate result.
For RE7 PC build, R9-390X's 5.9 TFLOPS number nears 980 Ti's 5.63 TFLOPS and 1070's 6.4 TFLOPS.
RE7's geometry load would be optimised for AMD GPUs.
Interesting observations. So, you twist the flux capacitor counter clockwise then insert the soloflange.
Away from display-related issues the PC version is otherwise excellent, although it only provides a modest visual jump over the base PS4 and Xbox One outside of resolution. For the most part, the core graphical make-up at max settings is very close to the PS4 Pro version, with only the occasional additional refinement on show. If there are improvements in shadows quality and reflections, the game's heavy use of post-processing means that these don't stand out during gameplay, or in like-for-like footage, where the visuals appear very closely matched. Even with high-end effects enabled (such as HBAO+ and very high shadows) it certainly feels like the console versions are holding their own here. That said, the PC version manages to avoid the frequent texture switching issues that are present on PS4 and the Pro, which provides a more consistent presentation as these artefacts rarely manifest at all.
RE7 PS4 non-Pro has 1080p/mostly 60 fps result. PS4 Pro's version is effectively 4X over PS4's version!
@ronvalencia: Numbers don't mean shit. Take rx 480 and gtx 1060, rx has better tflops than gtx 1060 still it doesn't beat it in most of the games.(except for few dx12 title which right now are so few in numbers that they don't even matter)
@ronvalencia: Numbers don't mean shit. Take rx 480 and gtx 1060, rx has better tflops than gtx 1060 still it doesn't beat it in most of the games.(except for few dx12 title which right now are so few in numbers that they don't even matter)
Numbers do mean shit when you're speaking of relative architecture and floating point performance attached to specific of same ilk hardware, the fact that you're trying to compare AMD and Nvidia cards in terms of Teraflops goes to show that you shouldn't be in this conversation to begin with.
I feel that with cross play coupled with scorpio and XBO with KB/M that usual pc only developers may start released what would be PC exclusives on xbox to test the water.
@dynamitecop: Just making the point where everyone is concerned with teraflops and the big numbers. They are not sole reason for performance boost.
They're not, but when you know the performance output of a specific manufacturers cards relative to Teraflops dating back multiple hardware generations and years, it's pretty easy to get an idea of where things fall.
@ronvalencia: Numbers don't mean shit. Take rx 480 and gtx 1060, rx has better tflops than gtx 1060 still it doesn't beat it in most of the games.(except for few dx12 title which right now are so few in numbers that they don't even matter)
Your post don't mean shit.
Any high TFLOPS claims will be bound by effective memory bandwidth!
R9-Fury X's raw 8.6 TFLOPS exposed with Vulkan+Async Compute+AMD Intrinsics+No Nvidia tessellation over draw politics (it wouldn't exist on consoles).
Async Compute workloads are usually out of phase with Sync Graphics Command's memory bandwidth access.
980 Ti's 6.4 TFLOPS gap with Fury X's 8.6 TFLOPS is 1.34X
Doom Vulkan's framerate gap between 980 Ti and Fury X is 1.30X
AMD GCN hardware is fine, but the AMD DX11/OGL driver is not on par with NVidia's DX11/OGL driver.
When there's sufficient shader (FLOPS) resources, the major bottleneck is the effective memory bandwidth i.e. ALUs needs to read and write the results to memory.
This is why AMD is pushing for HBM2 and why NAVI will get a new memory design..
For Vega GPUs, read http://www.anandtech.com/show/11002/the-amd-vega-gpu-architecture-teaser/3
ROPs & Rasterizers: Binning for the Win(ning)
We’ll suitably round-out our overview of AMD’s Vega teaser with a look at the front and back-ends of the GPU architecture. While AMD has clearly put quite a bit of effort into the shader core, shader engines, and memory, they have not ignored the rasterizers at the front-end or the ROPs at the back-end. In fact this could be one of the most important changes to the architecture from an efficiency standpoint.
Back in August, our pal David Kanter discovered one of the important ingredients of the secret sauce that is NVIDIA’s efficiency optimizations. As it turns out, NVIDIA has been doing tile based rasterization and binning since Maxwell, and that this was likely one of the big reasons Maxwell’s efficiency increased by so much. Though NVIDIA still refuses to comment on the matter, from what we can ascertain, breaking up a scene into tiles has allowed NVIDIA to keep a lot more traffic on-chip, which saves memory bandwidth, but also cuts down on very expensive accesses to VRAM.
For Vega, AMD will be doing something similar. The architecture will add support for what AMD calls the Draw Stream Binning Rasterizer, which true to its name, will give Vega the ability to bin polygons by tile. By doing so, AMD will cut down on the amount of memory accesses by working with smaller tiles that can stay-on chip. This will also allow AMD to do a better job of culling hidden pixels, keeping them from making it to the pixel shaders and consuming resources there.
As we have almost no detail on how AMD or NVIDIA are doing tiling and binning, it’s impossible to say with any degree of certainty just how close their implementations are, so I’ll refrain from any speculation on which might be better. But I’m not going to be too surprised if in the future we find out both implementations are quite similar. The important thing to take away from this right now is that AMD is following a very similar path to where we think NVIDIA captured some of their greatest efficiency gains on Maxwell, and that in turn bodes well for Vega.
Meanwhile, on the ROP side of matters, besides baking in the necessary support for the aforementioned binning technology, AMD is also making one other change to cut down on the amount of data that has to go off-chip to VRAM. AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache.
---------------------
As for RX-480, any overclock editions will be bounded by effective memory bandwidth.
For reference RX-480
((((256 bit x 8000Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 263.84 GB/s
--
Scorpio's "more than 320 GB/s memory bandwidth" claim.
((((384 bit x GDDR5-6900 Mhz) / 8) / 1024) x Polaris's 77.6 percent memory bandwidth efficiency) x Polaris's compression booster 1.36X = 341 .34 GB/s
PS;
((384 bit x GDDR5-6900 Mhz) / 8) / 1024) = 323 GB/s physical memory bandwidth.
((384 bit x GDDR5-7000 Mhz) / 8) / 1024) = 328 GB/s physical memory bandwidth.
Comparison.
The memory bandwidth gap between Fury X and R9-290 = 1.266X (random textures)
With Fury X, it's memory compression is inferior to NVIDIA's Maxwell.
The FLOPS gap between Fury X and R9-290 = 1.48X
The frame rate gap between R9-290X and Fury X is 1.19X.
Random texture memory bandwidth gap's 1.266X factor is closer to frame rate gap's 1.19X.FLOPS gap between R9-290X (5.8 TFLOPS)and Fury X (8.6 TFLOPS) plays very little part with frame rate gap.
With 980 Ti (5.63 TFLOPS), it's superior memory compression enables it to match Fury X's results.
Conclusion:
1. When there's enough FLOPS for a particular workload, effective memory bandwidth is better prediction method for higher grade GPUs.
2. The effective memory bandwidth between Fury X and 980 Ti are similar hence similar results.
-------------------
Example of near brain dead Xbox One ports running PC GPUs.
Frame rate difference between 980 Ti and R9-290X is 1.31X with Forza 6 Apex
Effective memory bandwidth between 980 Ti and R9-290X is 1.38X
Forza 6 Apex is another example for effective memory bandwidth influencing the frame rate result.
--------------
Another examples with near brain dead Xbox One ports running on PC GPUs.
R9-390X has 5.9 TFLOPS
GTX 980 Ti has 5.63 TFLOPS
GTX 1070 has 6.4 TFLOPS
R9-390X being near NVIDIA GPUs with similar TFLOPS range.
R9-290X has 5.6 TFLOPS
980 Ti has 5.63 TFLOPS.
R9-390X being near NVIDIA GPUs with similar TFLOPS range.
@ronvalencia: alright I get what you're saying but this shows that amd only perform better in dx12 titles and all the dx12 titles will favour amd but that's the problem there are very few dx12 games out there.
Away from display-related issues the PC version is otherwise excellent, although it only provides a modest visual jump over the base PS4 and Xbox One outside of resolution. For the most part, the core graphical make-up at max settings is very close to the PS4 Pro version, with only the occasional additional refinement on show. If there are improvements in shadows quality and reflections, the game's heavy use of post-processing means that these don't stand out during gameplay, or in like-for-like footage, where the visuals appear very closely matched. Even with high-end effects enabled (such as HBAO+ and very high shadows) it certainly feels like the console versions are holding their own here. That said, the PC version manages to avoid the frequent texture switching issues that are present on PS4 and the Pro, which provides a more consistent presentation as these artefacts rarely manifest at all.
RE7 PS4 non-Pro has 1080p/mostly 60 fps result. PS4 Pro's version is effectively 4X over PS4's version!
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
Resident evil 7 on the pro only runs at 1260p and gets upscaled to 4k, its a resolution boost but nowhere near 4k resolution.
Game runs at around ~80 fps constantly on a 970 1440p on my setup. Game hardly is taxing for any modern gpu.
Mantis burn racing, have you seen the game? thing would run on a potato 4k resolution. they probably locked it at 1080p as people would aspect it to be on that resolution. I can't see how that game couldn't come close to 4k already on a base ps4, unless it didn't support the output for it.
Also at vulcan it's a AMD focused API, it's bound to run better on that. doesn't mean a whole lot to this discussion.
Like i said before, fp16 is going to be a lot more expensive to develop for, as it will take a lot more time to get things going. and if it's going to work for complex games further down the line is the question.
Your statement about double the tflops is just false as it's not going to push anywhere near double the performance in any new game.
If fp16 was that great, we would already have had it in PC's decades ago. There is a reason why we didn't ( or it didn't succeeded ).
That nvidia and amd bolts those 16 fp onto there hardware again, is probably nothing else then boasting about theoretical peformance gain to sell there crap which is nothing new for them. Rather then useful advantage.
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
The only genre I see this being an issue with are First Person Shooters.
But MMOs and Fighters seem to do pretty well with the Cross Platform gaming. Heck even Co-Op games like Rocket League benefit for having Cross Platform Multiplayer.
First Person Shooters is a given taken that Controllers in general don't have the same precision that a mouse would have, but I don't see why other games have to be separated.
Microsoft is loosing everything from exclusives being cancelled like Scalebound, Fable Legends etc. To games selling poorly like Gears 4. MS new IPs selling poorly cuz Phil Spencer Half Ass the games like Recore & never to see a sequel cuz Phil Spencer is a cheap ass. The bad media is killing the Xbox with 500,000 plus of people listening to how bad MS is doing with bad articles & Youtube videos
The XB1 is WAY behind the PS4 by 25 million consoles. Imagine how worse it will be by the time Scorpio comes out...sweet jesus. The PS4 has exclusives with mega hype along with the Nintendo Switch which is getting huge hype & SuperBowl Ads. The consoles will be cheap during the holidays along with the PS4 Pro bundled with games which will HURT Scorpio which WILL be $500 or $600. The Xbox S 2TB model was $400 so Scorpio will be much more expensive. Scorpio can't compete with the cheaper consoles, along with PS4/ Switch Exclusives.
The Xbox launched in 2001 after the PS2 came out & did not make a dent on Sony. Now MS is in worse shape then ever thx to Phil Axemen Spencer as i've stated. Xbox is in big trouble unless they do what they have to & get rid of Phil Spencer the stupid idiot or else the future looks like shit for Xbox cuz of PHIL!!
It is actually behind by 31 million now but the rest of your post is spot on.
Halo 1 and 2 were on PC, it's not a new demographic.
As for cross play, console gamers and their controllers are not going to be wanting to play against PC gamers with m/kb set ups for very long. There's only so many times a person can categorically lose before they stop playing.
Scorpio is only a rumour right now but even if those rumours are true my PC built in 2014/15 is already more powerful.
The only genre I see this being an issue with are First Person Shooters.
But MMOs and Fighters seem to do pretty well with the Cross Platform gaming. Heck even Co-Op games like Rocket League benefit for having Cross Platform Multiplayer.
First Person Shooters is a given taken that Controllers in general don't have the same precision that a mouse would have, but I don't see why other games have to be separated.
As I said in a previous reply, this is a Halo 6 thread with some extra dressing, thus the comment about KB/M v controllers
@GarGx1: that's and easy fix though. You can either A.) let Xbox users use Kb mouse, or B.) have a separate game mode for cross play on PC that forces the PC players to use a controller.
Away from display-related issues the PC version is otherwise excellent, although it only provides a modest visual jump over the base PS4 and Xbox One outside of resolution. For the most part, the core graphical make-up at max settings is very close to the PS4 Pro version, with only the occasional additional refinement on show. If there are improvements in shadows quality and reflections, the game's heavy use of post-processing means that these don't stand out during gameplay, or in like-for-like footage, where the visuals appear very closely matched. Even with high-end effects enabled (such as HBAO+ and very high shadows) it certainly feels like the console versions are holding their own here. That said, the PC version manages to avoid the frequent texture switching issues that are present on PS4 and the Pro, which provides a more consistent presentation as these artefacts rarely manifest at all.
RE7 PS4 non-Pro has 1080p/mostly 60 fps result. PS4 Pro's version is effectively 4X over PS4's version!
Mantis Burn Racing PS4 Pro version reached 4K/60 fps which is 4X effectiveness over the original PS4 version's 1080p/60 fps.
Resident evil 7 on the pro only runs at 1260p and gets upscaled to 4k, its a resolution boost but nowhere near 4k resolution.
Game runs at around ~80 fps constantly on a 970 1440p on my setup. Game hardly is taxing for any modern gpu.
Mantis burn racing, have you seen the game? thing would run on a potato 4k resolution. they probably locked it at 1080p as people would aspect it to be on that resolution. I can't see how that game couldn't come close to 4k already on a base ps4, unless it didn't support the output for it.
Also at vulcan it's a AMD focused API, it's bound to run better on that. doesn't mean a whole lot to this discussion.
Like i said before, fp16 is going to be a lot more expensive to develop for, as it will take a lot more time to get things going. and if it's going to work for complex games further down the line is the question.
Your statement about double the tflops is just false as it's not going to push anywhere near double the performance in any new game.
If fp16 was that great, we would already have had it in PC's decades ago. There is a reason why we didn't ( or it didn't succeeded ).
That nvidia and amd bolts those 16 fp onto there hardware again, is probably nothing else then boasting about theoretical peformance gain to sell there crap which is nothing new for them. Rather then useful advantage.
Resolution is 2240x1260 which has 2,822,400 pixels.









































Log in to comment