John Carmack:You need a 3.68 Teraflop GPU to match PS4's GPU
This topic is locked from further discussion.

quake invented pro gaming like todd hollenshead said show me anyone saying their multiplayer is ''player skill based balanced'' multiplayer lol.

[QUOTE="ronvalencia"]
Crytek's Cevat Yerli >>>>>>>>>>>>>> you
me >>>>>>>>>>>>>>>> you. I work as C++ programmer on Windows.
tormentos
I don't care the info i posted >>>>>>>>>>>>>>>>>>>>>>> yours...
Confirmed HSA is a design and i prove it stand alone GPU will not benefit like APU will period,and that came from AMD..
AMD >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> you.
:lol:
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
[QUOTE="tormentos"]
[QUOTE="ronvalencia"]
Crytek's Cevat Yerli >>>>>>>>>>>>>> you
me >>>>>>>>>>>>>>>> you. I work as C++ programmer on Windows.
kalipekona
I don't care the info i posted >>>>>>>>>>>>>>>>>>>>>>> yours...
Confirmed HSA is a design and i prove it stand alone GPU will not benefit like APU will period,and that came from AMD..
AMD >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> you.
:lol:
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
HSA software can be implemented without HSA hardware, its a api spec that automatically shifts workloads to different processors, video cards on the other hand supported IOMMU and reading from main memory for some time and needed to be enabled in the motherboard.The OS has to use the IOMMU and cpu MMU so there is some synchronization going on in the cpu side in the OS. rov can post as many documents as he likes about HSA on current video cards but the fact is the hardware doesn't support it and the software manages it virtually as one address space. Its not a unified pool of memory and there is overhead for the CPU/GPU stepping out of it's bounds.
The gpu has to copy memory over pci-e to be able to use it, it's physically impossible for it to read from the memory bus directly which is HSA architecture.
PS4/360 basically has a single memory bus so there is zero overhead for memory access for both processors, like APUs, the HSA will work better on those systems because pointers are far more efficient in a system where the entire memory space is unified in hardware and there are no penalties for the processors as there are no bounded memory ranges for each.
edit: %(@# you gamespot, all those returns just dissapear... wtf kind of coding is this? Does rov work here?
Well. That was certainly... interesting :|

[QUOTE="AdobeArtist"]
Well. That was certainly... interesting :|
wis3boi
Thanks for laying waste to that moron :D
My jaw dropped when I saw just how many reports there were (at least 90% all valid too). That was the mod equivelent to the load of paperwork to pile through :lol: :P
[QUOTE="wis3boi"]
[QUOTE="AdobeArtist"]
Well. That was certainly... interesting :|
AdobeArtist
Thanks for laying waste to that moron :D
My jaw dropped when I saw just how many reports there were (at least 90% all valid too). That was the mod equivelent to the load of paperwork to pile through :lol: :P


[QUOTE="wis3boi"]
[QUOTE="AdobeArtist"]
Thanks for laying waste to that moron :D
AdobeArtist
My jaw dropped when I saw just how many reports there were (at least 90% all valid too). That was the mod equivelent to the load of paperwork to pile through :lol: :P

[QUOTE="kalipekona"]
[QUOTE="tormentos"]
I don't care the info i posted >>>>>>>>>>>>>>>>>>>>>>> yours...
Confirmed HSA is a design and i prove it stand alone GPU will not benefit like APU will period,and that came from AMD..
AMD >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> you.
:lol:
savagetwinkie
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
HSA software can be implemented without HSA hardware, its a api spec that automatically shifts workloads to different processors, video cards on the other hand supported IOMMU and reading from main memory for some time and needed to be enabled in the motherboard.The OS has to use the IOMMU and cpu MMU so there is some synchronization going on in the cpu side in the OS. rov can post as many documents as he likes about HSA on current video cards but the fact is the hardware doesn't support it and the software manages it virtually as one address space. Its not a unified pool of memory and there is overhead for the CPU/GPU stepping out of it's bounds.
The gpu has to copy memory over pci-e to be able to use it, it's physically impossible for it to read from the memory bus directly which is HSA architecture.
PS4/360 basically has a single memory bus so there is zero overhead for memory access for both processors, like APUs, the HSA will work better on those systems because pointers are far more efficient in a system where the entire memory space is unified in hardware and there are no penalties for the processors as there are no bounded memory ranges for each.
edit: %(@# you gamespot, all those returns just dissapear... wtf kind of coding is this? Does rov work here?
You are making a claim that you don't know about. For example, before you can use the FPU (in memory protect OS model), the OS has to know about the FPU i.e. it's the OS that manages the FPU resource. Same thing with multi-CPU (SMP) and SSE support.
The OS doesn't automatically know about MMU, it has to be programmed into the OS. You got operating systems like Tripos (the basis for AmigaOS 1.0) doesnt know about MMU.
A HSA driver is required to manage the additonal resources.
---------------
well he finally made it to level 10 at last..he always dies at level 5 or 7.
[QUOTE="kalipekona"]
[QUOTE="tormentos"]
I don't care the info i posted >>>>>>>>>>>>>>>>>>>>>>> yours...
Confirmed HSA is a design and i prove it stand alone GPU will not benefit like APU will period,and that came from AMD..
AMD >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> you.
:lol:
savagetwinkie
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
HSA software can be implemented without HSA hardware, its a api spec that automatically shifts workloads to different processors, video cards on the other hand supported IOMMU and reading from main memory for some time and needed to be enabled in the motherboard.
The OS has to use the IOMMU and cpu MMU so there is some synchronization going on in the cpu side in the OS. rov can post as many documents as he likes about HSA on current video cards but the fact is the hardware doesn't support it and the software manages it virtually as one address space. Its not a unified pool of memory and there is overhead for the CPU/GPU stepping out of it's bounds.
The gpu has to copy memory over pci-e to be able to use it, it's physically impossible for it to read from the memory bus directly which is HSA architecture.
PS4/360 basically has a single memory bus so there is zero overhead for memory access for both processors, like APUs, the HSA will work better on those systems because pointers are far more efficient in a system where the entire memory space is unified in hardware and there are no penalties for the processors as there are no bounded memory ranges for each.
edit: %(@# you gamespot, all those returns just dissapear... wtf kind of coding is this? Does rov work here?
HSAIL is an instruction set spec i.e. IL = intermediate language. To have "full HSAIL", the hardware should support the software requirements.
AMD haven't stated "full HSAIL" for older Radeon HDs.
Xbox 360 has two memory pools i.e. 10MB EDRAM and GDDR3 memory pools. Both Xbox (NV2A) and PS4 has a single physical memory pool.
---------------------
You are forgetting memory expansion add-on cards via PCI-E.
http://www.rakuten.com/prod/intel-8-dimm-pci-express-x16-memory-expansion-board-64gb-ddr2-sdram-8/205583837.html
These boards expands PC's system memory via PCI-E slots. HSA GPU add-on cards are similar to Intel's memory expansion boards i.e. both adds additional memory pool to system memory via unified virtual memory address methods. Both boards operate via PCI-E's Address Translation Services (ATS) and Page Request Interface (PRI) extension.
From Intel Core i7's POV, PCI-E bus is being use as a "front side bus" for the memory pool seating on the PCI-E bus.
----------------------
PowerPoint Slide for AMD Radeon HD 7xx0 GCN.
http://www.brightsideofnews.com/news/2011/11/30/radeon-hd-7000-revealed-amd-to-mix-gcn-with-vliw4--vliw5-architectures.aspx

Address Translation Services (ATS) and Page Request Interface (PRI) extension is defined by PCI-SIG PCIe standards.
Note why I stated the PC has both X1 and PS4 characteristics.

[QUOTE="wis3boi"]
[QUOTE="AdobeArtist"]
Well. That was certainly... interesting :|
mitu123
Thanks for laying waste to that moron :D
He should had been banned a lot sooner, lol.Yeah, not to criticize the mods (who do an awesome job with the rules/power they're given) but it's so beyond obvious that its him everytime he makes a new account that its crazy how he lasts that long.
HSA software can be implemented without HSA hardware, its a api spec that automatically shifts workloads to different processors, video cards on the other hand supported IOMMU and reading from main memory for some time and needed to be enabled in the motherboard.[QUOTE="savagetwinkie"]
[QUOTE="kalipekona"]
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
ronvalencia
The OS has to use the IOMMU and cpu MMU so there is some synchronization going on in the cpu side in the OS. rov can post as many documents as he likes about HSA on current video cards but the fact is the hardware doesn't support it and the software manages it virtually as one address space. Its not a unified pool of memory and there is overhead for the CPU/GPU stepping out of it's bounds.
The gpu has to copy memory over pci-e to be able to use it, it's physically impossible for it to read from the memory bus directly which is HSA architecture.
PS4/360 basically has a single memory bus so there is zero overhead for memory access for both processors, like APUs, the HSA will work better on those systems because pointers are far more efficient in a system where the entire memory space is unified in hardware and there are no penalties for the processors as there are no bounded memory ranges for each.
edit: %(@# you gamespot, all those returns just dissapear... wtf kind of coding is this? Does rov work here?
You are forgetting memory expansion add-on cards via PCI-E.
http://www.rakuten.com/prod/intel-8-dimm-pci-express-x16-memory-expansion-board-64gb-ddr2-sdram-8/205583837.html
These boards expands PC's system memory via PCI-E slots. HSA GPU add-on cards are similar to Intel's memory expansion boards i.e. both adds additional memory pool to system memory via unified virtual memory address methods. Both boards operate via PCI-E's Address Translation Services (ATS) and Page Request Interface (PRI) extension.
From Intel Core i7's POV, PCI-E bus is being use as a "front side bus" for the memory pool seating on the PCI-E bus.
----------------------
PowerPoint Slide for AMD Radeon HD 7xx0 GCN.
http://www.brightsideofnews.com/news/2011/11/30/radeon-hd-7000-revealed-amd-to-mix-gcn-with-vliw4--vliw5-architectures.aspx
Address Translation Services (ATS) and Page Request Interface (PRI) extension is defined by PCI-SIG PCIe standards.

This means weapon balance and that the game requires skill. No easy assualt rifle kills like you have in todays games. If you took Quake Live and let everyone spawn with the lightning gun, give everyone quad damage and cut movement speed in half you get Cod and BF.http://www.youtube.com/watch?v=4XoSIZ0bHdY
Todd Hollenshead says id Software is Watching
3:15 our philosophy are games are based on a even playing field and player skill
pcgamingowns
[QUOTE="DrTrafalgarLaw"]unreal tournament was just noobs camping with sniper rifles like any modern game Lol no and those that did camp had to get either a headshot or 2 bodyshots on much faster moving targets.I remember quake...and how it pales in comparison to Unreal Tournament. HeeWee...you need to let go. Quake will there always be for you, by your side. In times of hardship, in drought, in joy and euforia. When your firstborn takes his or her first steps, just show him/her how to play Quake. Sure he/she won't understand but at least it'll be a memento from a crazy father that got locked up in a mental ward for yelling QUAKE!!! in an empty mall on a sunday night.
pcgamingowns
You always bring up something that is not salient to the point being made and I do not understand why. What he is saying is very simple. HSA works with a discreet GPU but because of the latency of transferring data from the main memory pool to the GPU memory pool (even if both memory pools are treated as one from a software point of view there is still a slow ass bus sitting between them) there are latency issues which means this setup is unsuitable for certain workloads. A good example of this would be physics. With Nvidia PhysX you can use the GPU to do some physics calculations but this does not actually affect the simulation because the simulation is running on the CPU and the performance penalty for working out the physics of a scene, passing that data back to the CPU memory pool and then allowing the CPU to simulate those results is too large. With HSA on a physical UMA you can have physics running on the GPU that affects the actual simulation though because the data is written to and from the same pool of memory which both the GPU and the CPU can access without the latency penalty.
btk2k2
PCI-E doesn't have 60 ms (four frame) latency.
PS; ms = millisecond. https://en.wikipedia.org/wiki/Millisecond
You always miss some important details e.g. you still missed the following slide.
PowerPoint Slide for AMD Radeon HD 7xx0 GCN.
http://www.brightsideofnews.com/news/2011/11/30/radeon-hd-7000-revealed-amd-to-mix-gcn-with-vliw4--vliw5-architectures.aspx
To have proper real time GpGPU compute with under 16ms results turnaround (to CPU), one dumps DX ComputeShader.
----
NVIDIA has Tesla Compute Cluster (TCC) driver that enables unified virtual address mode (since NVIDIA Fermi) and low latency CUDA/OpenCL dispatches i.e. it bypass latency loaded Microsoft's WDM and DX.
NVIDIA has been marketing low latency CUDA/OpenCL driver in server/HPC market and smashing AMD with it. You should realised by now why AMD GCN haven't made large in-roads in the server/HPC market i.e. AMD's current driver is $hit for HPC.
Practical PCI-E latency example with old PC hardware (reverting back to my NVIDIA mode).
About 6.5 microseconds (for host to device) and 11 microseconds (for device to host with display attached).
Hardware spec: Intel X5570 (Nehalem) + Tesla C2050 + Fedora 13 (x86_64, 2.6.34.7-61) + NVIDIA Driver 260.19.21/CUDA 3.2.16 + GCC 4.4.5
Intel Nehalem = 1st gen Intel Core iX and it doesn't support PCI-E version 3.0 (with Intel Ivybridge).
PS; microseconds = us http://en.wikipedia.org/wiki/Microsecond
~17.7 microseconds turn around is more than enough for 16 ms frame render.
You don't know what youre talking about. PCI-E version 3.0 with 16 lanes is reasonably fast external bus i.e. 32GB/s full duplex bandwidth.
IF PCI-E is not the problem, guess who caused the massive latency in the PC? Hint; it's starting with the letter M.
NVIDIA fanboys would LOL at your statements.


f*ck?

Ouch, poor Hermits, none of them have a titan here
Davekeeh
I could CrossFire my 7950/7970(similar to 7990) into my main desktop PC.

You always bring up something that is not salient to the point being made and I do not understand why. What he is saying is very simple. HSA works with a discreet GPU but because of the latency of transferring data from the main memory pool to the GPU memory pool (even if both memory pools are treated as one from a software point of view there is still a slow ass bus sitting between them) there are latency issues which means this setup is unsuitable for certain workloads. A good example of this would be physics. With Nvidia PhysX you can use the GPU to do some physics calculations but this does not actually affect the simulation because the simulation is running on the CPU and the performance penalty for working out the physics of a scene, passing that data back to the CPU memory pool and then allowing the CPU to simulate those results is too large. With HSA on a physical UMA you can have physics running on the GPU that affects the actual simulation though because the data is written to and from the same pool of memory which both the GPU and the CPU can access without the latency penalty.btk2k2
Oh i do he does it to inject some lame theory of him in order to not lose the argument.
Yesterday he bring the 7850 PC card to prove the xbox one Soc did not suffer from heat issues,because some how in his small mind he thinks that making a 7850 GPU is the same as making an APU with an 8core CPU and a 1.6 billion transistor ESRAM.
He also bring the w5000S which is a workstation GPU,because for him it represent the xbox one better,than the gimped 7790 with 2 less CU and 200 mhz lower clock.
He will also bring Intel CPU into the argument when he want to make a point that something is possible on PC,but completely ignoring Intel is not the xbox one CPU maker,arguing with him is hard,because you confront him with something like i did with HSA,and he will bring 30 thing not related and completely ignore your point.
Even when the point come from AMD them self.
[QUOTE="btk2k2"]
You always bring up something that is not salient to the point being made and I do not understand why. What he is saying is very simple. HSA works with a discreet GPU but because of the latency of transferring data from the main memory pool to the GPU memory pool (even if both memory pools are treated as one from a software point of view there is still a slow ass bus sitting between them) there are latency issues which means this setup is unsuitable for certain workloads. A good example of this would be physics. With Nvidia PhysX you can use the GPU to do some physics calculations but this does not actually affect the simulation because the simulation is running on the CPU and the performance penalty for working out the physics of a scene, passing that data back to the CPU memory pool and then allowing the CPU to simulate those results is too large. With HSA on a physical UMA you can have physics running on the GPU that affects the actual simulation though because the data is written to and from the same pool of memory which both the GPU and the CPU can access without the latency penalty.
ronvalencia
PCI-E doesn't have 60 ms (four frame) latency.
PS; ms = millisecond. https://en.wikipedia.org/wiki/Millisecond
You always miss some important details e.g. you still missed the following slide.
PowerPoint Slide for AMD Radeon HD 7xx0 GCN.
http://www.brightsideofnews.com/news/2011/11/30/radeon-hd-7000-revealed-amd-to-mix-gcn-with-vliw4--vliw5-architectures.aspx
To have proper real time GpGPU compute with under 16ms results turnaround (to CPU), one dumps DX ComputeShader.
----
NVIDIA has Tesla Compute Cluster (TCC) driver that enables unified virtual address mode (since NVIDIA Fermi) and low latency CUDA/OpenCL dispatches i.e. it bypass latency loaded Microsoft's WDM and DX.
NVIDIA has been marketing low latency CUDA/OpenCL driver in server/HPC market and smashing AMD with it. You should realised by now why AMD GCN haven't made large in-roads in the server/HPC market i.e. AMD's current driver is $hit for HPC.
Practical PCI-E latency example with old PC hardware (reverting back to my NVIDIA mode).
About 6.5 microseconds (for host to device) and 11 microseconds (for device to host with display attached).
Hardware spec: Intel X5570 (Nehalem) + Tesla C2050 + Fedora 13 (x86_64, 2.6.34.7-61) + NVIDIA Driver 260.19.21/CUDA 3.2.16 + GCC 4.4.5
Intel Nehalem = 1st gen Intel Core iX and it doesn't support PCI-E version 3.0 (with Intel Ivybridge).
PS; microseconds = us http://en.wikipedia.org/wiki/Microsecond
~17.7 microseconds turn around is more than enough for 16 ms frame render.
You don't know what youre talking about. PCI-E version 3.0 with 16 lanes is reasonably fast external bus i.e. 32GB/s full duplex bandwidth.
IF PCI-E is not the problem, guess who caused the massive latency in the PC? Hint; it's starting with the letter M.
NVIDIA fanboys would LOL at your statements.
HSA will not work on dedicated GPU setups like it will on an APU and AMD them self say so period you loss.
You can bring all the lame argumenst you want APU are full HSA dedicated GPU on PC are not,AMD say so.
[QUOTE="btk2k2"]You always bring up something that is not salient to the point being made and I do not understand why. What he is saying is very simple. HSA works with a discreet GPU but because of the latency of transferring data from the main memory pool to the GPU memory pool (even if both memory pools are treated as one from a software point of view there is still a slow ass bus sitting between them) there are latency issues which means this setup is unsuitable for certain workloads. A good example of this would be physics. With Nvidia PhysX you can use the GPU to do some physics calculations but this does not actually affect the simulation because the simulation is running on the CPU and the performance penalty for working out the physics of a scene, passing that data back to the CPU memory pool and then allowing the CPU to simulate those results is too large. With HSA on a physical UMA you can have physics running on the GPU that affects the actual simulation though because the data is written to and from the same pool of memory which both the GPU and the CPU can access without the latency penalty.tormentos
Oh i do he does it to inject some lame theory of him in order to not lose the argument.
Yesterday he bring the 7850 PC card to prove the xbox one Soc did not suffer from heat issues,because some how in his small mind he thinks that making a 7850 GPU is the same as making an APU with an 8core CPU and a 1.6 billion transistor ESRAM.
He also bring the w5000S which is a workstation GPU,because for him it represent the xbox one better,than the gimped 7790 with 2 less CU and 200 mhz lower clock.
He will also bring Intel CPU into the argument when he want to make a point that something is possible on PC,but completely ignoring Intel is not the xbox one CPU maker,arguing with him is hard,because you confront him with something like i did with HSA,and he will bring 30 thing not related and completely ignore your point.
Even when the point come from AMD them self.
No, sometimes the points he makes simply go over some of your heads.
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
kalipekona
No it was not and the second link is straight from AMD..:lol:
To have full HSA you need hUMA good luck getting that on current systems with 2 memory pools.
No, sometimes the points he makes simply go over some of your heads.
kalipekona
No bringing the damn 7850 to make a point about the xbox one having no heat issues is one of teh most stupid things ever,the damn 7850 on PC doesn't have an 8 core CPU with an 1.6 Billion transistor ESRAM that add complexity to the chip been created,the hell to begin with the 7850 is not inside the xbox one.
Comparing console heat vs PC heat is a joke PC had better air flow and fans can even be change at your liking.
You talk about Cars been heavy and he bring a Bicycle into the argument is frustrating,he is to hard headed,and will be some incredible theories fuel by him only to defend his point.
Either been PRT only working on xbox one and not on PS4 when is a GCN feature.
Or Jit compression which he believe apparently that is xbox one exclusive..
[QUOTE="kalipekona"]
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
tormentos
No it was not and the second link is straight from AMD..:lol:
To have full HSA you need hUMA good luck getting that on current systems with 2 memory pools.
My slides was also from AMD. :lol:
I also posted Intel's system memory expansion solution via PCI-E (which acts like the front side bus) example.
You miss the words "not necessary" for the memory copy process.
[QUOTE="kalipekona"] [QUOTE="tormentos"]
[QUOTE="ronvalencia"]
[QUOTE="btk2k2"]
You always bring up something that is not salient to the point being made and I do not understand why. What he is saying is very simple. HSA works with a discreet GPU but because of the latency of transferring data from the main memory pool to the GPU memory pool (even if both memory pools are treated as one from a software point of view there is still a slow ass bus sitting between them) there are latency issues which means this setup is unsuitable for certain workloads. A good example of this would be physics. With Nvidia PhysX you can use the GPU to do some physics calculations but this does not actually affect the simulation because the simulation is running on the CPU and the performance penalty for working out the physics of a scene, passing that data back to the CPU memory pool and then allowing the CPU to simulate those results is too large. With HSA on a physical UMA you can have physics running on the GPU that affects the actual simulation though because the data is written to and from the same pool of memory which both the GPU and the CPU can access without the latency penalty.
tormentos
PCI-E doesn't have 60 ms (four frame) latency.
PS; ms = millisecond. https://en.wikipedia.org/wiki/Millisecond
You always miss some important details e.g. you still missed the following slide.
PowerPoint Slide for AMD Radeon HD 7xx0 GCN.
http://www.brightsideofnews.com/news/2011/11/30/radeon-hd-7000-revealed-amd-to-mix-gcn-with-vliw4--vliw5-architectures.aspx
To have proper real time GpGPU compute with under 16ms results turnaround (to CPU), one dumps DX ComputeShader.
----
NVIDIA has Tesla Compute Cluster (TCC) driver that enables unified virtual address mode (since NVIDIA Fermi) and low latency CUDA/OpenCL dispatches i.e. it bypass latency loaded Microsoft's WDM and DX.
NVIDIA has been marketing low latency CUDA/OpenCL driver in server/HPC market and smashing AMD with it. You should realised by now why AMD GCN haven't made large in-roads in the server/HPC market i.e. AMD's current driver is $hit for HPC.
Practical PCI-E latency example with old PC hardware (reverting back to my NVIDIA mode).
About 6.5 microseconds (for host to device) and 11 microseconds (for device to host with display attached).
Hardware spec: Intel X5570 (Nehalem) + Tesla C2050 + Fedora 13 (x86_64, 2.6.34.7-61) + NVIDIA Driver 260.19.21/CUDA 3.2.16 + GCC 4.4.5
Intel Nehalem = 1st gen Intel Core iX and it doesn't support PCI-E version 3.0 (with Intel Ivybridge).
PS; microseconds = us http://en.wikipedia.org/wiki/Microsecond
~17.7 microseconds turn around is more than enough for 16 ms frame render.
You don't know what youre talking about. PCI-E version 3.0 with 16 lanes is reasonably fast external bus i.e. 32GB/s full duplex bandwidth.
IF PCI-E is not the problem, guess who caused the massive latency in the PC? Hint; it's starting with the letter M.
NVIDIA fanboys would LOL at your statements.
HSA will not work on dedicated GPU setups like it will on an APU and AMD them self say so period you loss.
You can bring all the lame argumenst you want APU are full HSA dedicated GPU on PC are not,AMD say so.
The slide I posted was also from AMD and the slide is pretty simple.
You have an assumption that PC can't expand it's system memory via PCI-E slots and treated like any other system memory.
The memory located on PCI-E bus is like another memory controller channel.
[QUOTE="kalipekona"]
No, sometimes the points he makes simply go over some of your heads.
tormentos
No bringing the damn 7850 to make a point about the xbox one having no heat issues is one of teh most stupid things ever,the damn 7850 on PC doesn't have an 8 core CPU with an 1.6 Billion transistor ESRAM that add complexity to the chip been created,the hell to begin with the 7850 is not inside the xbox one.
Comparing console heat vs PC heat is a joke PC had better air flow and fans can even be change at your liking.
You talk about Cars been heavy and he bring a Bicycle into the argument is frustrating,he is to hard headed,and will be some incredible theories fuel by him only to defend his point.
Either been PRT only working on xbox one and not on PS4 when is a GCN feature.
Or Jit compression which he believe apparently that is xbox one exclusive..
W5000 (75 watt, powering 12 CUs) has a TDP less than 7790 (85 watt, powering 14 CUs). :lol:
75 watts TDP is lower than 7850's 130 watts (powering 16 CUs).
On the PRT issue, "less value" doesn't mean the feature is missing. :roll: You can see only black or white.
[QUOTE="tormentos"]
[QUOTE="kalipekona"]
The info you posted was an assumption by a guy that works for a PC site. Do you know how many times I've seen guys like that make huge assumptions that turn out to be false?
The fact that AMD themselves are talking about HSA with a discreet GPU is evidence enough alone.
ronvalencia
No it was not and the second link is straight from AMD..:lol:
To have full HSA you need hUMA good luck getting that on current systems with 2 memory pools.
My slides was also from AMD. :lol:
I also posted Intel's system memory expansion solution via PCI-E (which acts like the front side bus) example.
You miss the words "not necessary" for the memory copy process.
I looked into the Nvidia documentation regarding the PCI-E latency and you 17us example is valid in a set of strict constraints. From the information I read the h2d latency for data upto 4KB is 15us as is the d2h latency. Total round trip time is 30us. Above 4KB this latency increases, at 256KB for example it is around 50us each way so a 100us round trip. On top of the trip time itself you also have the dispatch overhead as well as the compute time. If you need to pass some data across the bus a few times to get the correct physics interaction you can easily exceed your desired frame time. This is why the latency kills HSA on a discrete GPU, its possible and in some circumstances it is useful but for the most part HSA is limited to APUs. More can be read here http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/.[QUOTE="ronvalencia"][QUOTE="tormentos"]
No it was not and the second link is straight from AMD..:lol:
To have full HSA you need hUMA good luck getting that on current systems with 2 memory pools.
btk2k2
My slides was also from AMD. :lol:
I also posted Intel's system memory expansion solution via PCI-E (which acts like the front side bus) example.
You miss the words "not necessary" for the memory copy process.
I looked into the Nvidia documentation regarding the PCI-E latency and you 17us example is valid in a set of strict constraints. From the information I read the h2d latency for data upto 4KB is 15us as is the d2h latency. Total round trip time is 30us. Above 4KB this latency increases, at 256KB for example it is around 50us each way so a 100us round trip. On top of the trip time itself you also have the dispatch overhead as well as the compute time. If you need to pass some data across the bus a few times to get the correct physics interaction you can easily exceed your desired frame time. This is why the latency kills HSA on a discrete GPU, its possible and in some circumstances it is useful but for the most part HSA is limited to APUs. More can be read here http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/.Your not disclosing the additional information i.e. cudaMemcpy() call is exceeding the pure PCIe latency. The benchmark is using the older CUDA 3.2.
NVIDIA's cudaMemcpy() call is different to AMD's "don't move the data" slide and it didn't avoid the copy process.
CUDA 4.0 comes with unified addressing and "no copy pinning of the system memory". http://www.anandtech.com/show/4198/nvidia-announces-cuda-40
-------------------------------
On AMD's side.
http://developer.amd.com/wordpress/media/2013/06/6-Demers-FINAL.pdf
HSA to be extended to Discrete GPU.

http://fabricengine.com/2012/07/gpu_computation_technology_preview/
The AMD HSA technology platform has the goal of providing a heterogeneous computation platform in which both CPU and GPU cores access and manipulate memory identically. HSA will enable complex data structures with pointer indirection to be shared between the CPU and GPU. Not only will no copying of data between different memory spaces be necessary, but the pointers imbedded in a complex data structure will be usable without change on both CPU and GPU cores
...
The animated scene was run on a workstation with an AMD A10-5800K APU with both integrated graphics and a discrete Radeon HD 7800 card; however, only the discrete card was used for GPU computation and OpenGL rendering for these tests
[QUOTE="btk2k2"] I looked into the Nvidia documentation regarding the PCI-E latency and you 17us example is valid in a set of strict constraints. From the information I read the h2d latency for data upto 4KB is 15us as is the d2h latency. Total round trip time is 30us. Above 4KB this latency increases, at 256KB for example it is around 50us each way so a 100us round trip. On top of the trip time itself you also have the dispatch overhead as well as the compute time. If you need to pass some data across the bus a few times to get the correct physics interaction you can easily exceed your desired frame time. This is why the latency kills HSA on a discrete GPU, its possible and in some circumstances it is useful but for the most part HSA is limited to APUs. More can be read here http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/.ronvalencia
Your not disclosing the additional information i.e. cudaMemcpy() call is exceeding the pure PCIe latency.
NVIDIA's cudaMemcpy() call is different to AMD's "don't move the data" slide.
http://developer.amd.com/wordpress/media/2013/06/6-Demers-FINAL.pdf
You are the one that brought up Nvidia to show that the PCIe latency was low and I am just showing that the example you gave was correct in a specific set of constraints and is not a general rule. I am fully aware it is different to the slide but I love that you do not quote the text from the article the slide is from. Here is the snippet that you are not disclosing. (Emphasis added)The new GCN architecture brings numerous innovations to GPU architecture, out of which we see x86 virtual memory as perhaps one of the most important ones. While the GPU manufacturers have promised functional virtual memory for ages, this is the first time we're seeing a working implementation. This is not a marketing gimmick, IOMMU is a fully functional GPU feature, supporting page faults, over allocating and even accepting 64-bit x86 memory pointers for 100% compatibility with 64-bit CPUs. Virtual memory is going to be the large part of next-gen Fusion APUs (2013) and FireStream GPGPU cards (2012), and we can only commend the effort made in making this possible.Bright Side of NewsYou see the part where it says it will be a large part of Fusion APUs, that would be the HSA portion of this technology. The FireStream GPGPU is the HPC side which is a totally different thing. For HPC think folding or bitcoin (as more widely known examples), you take a data set, dump it on the GPU and let it churn through it. It does not require a lot of back and forth communication with the CPU so the latency hit is worth it for the extra performance. Bottom line is that HSA on a physical UMA is going to be better than HSA on a discrete GPU with a virtual UMA because the overheads are massively reduced. If you want to argue with this point, the main point I am making (and others have made), then feel free but since AMD say the same thing I am saying then you would be disagreeing with the hardware manufacturer themselves, which is a sticky position to put yourself in. http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/. EDIT: And LOL at your second slide, WOW. It says exactly what others have been saying, the first step to HSA is to integrate the GPU and CPU on a single piece of silicone and use a unified memory architecture so the GPU and CPU can access the same pool of ram. Exactly what both console do and PCs with APUs do. It does no mention discrete GPUs at all. EDIT2: To reply to your edits. RTFA. Anandtech state that it just moves the memory management from the developers to the drivers. It still happens because for the discrete GPU to have the data in its local registers it has to get it from some where. If it is in the main memory pool then it needs to copy it over PCIe bus. This is unavoidable because it is the physical reality of how it works. Just because the dev can see it as one pool of memory to make development easier does not mean that this is not going on in the background. Unless you think that Cuda 4 is made of magic pixie dust that enables a GPU to work on a data set that is physically stored in the main memory pool (so not the GPUs local memory pool) without transferring it over to its local registers in some way. EDIT3: Final Edit. Just look at the slide that is in the article, I will try to link it for you
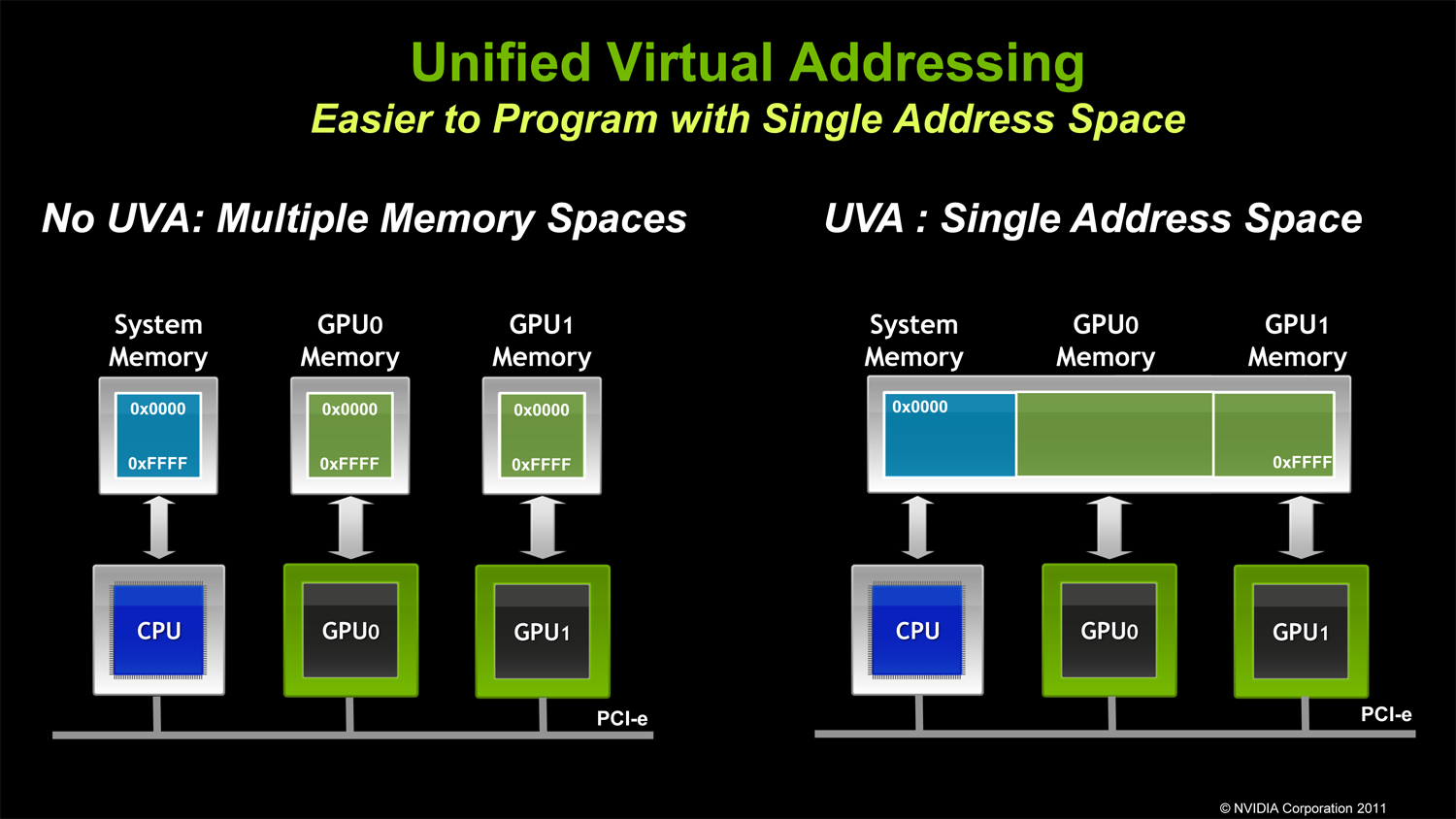 You see that the CPU and both GPUs in that slide have direct access to their local memory pool. In the sample on the right you have two bits of information, one stored in the CPUs memory pool and one stored in GPU1s memory pool, if the CPU wants what it stored in GPU1s memory pool it has to access it via the PCIe bus. Same for GPU0 if it wants to access what is stored in the CPUs or GPU1s memory pool. It just makes development easier as you do not have to manage where your data is, it is done for you but any cross memory requests still go via PCIe and still incur the latency hit. Nvidia are obviously confident that their drivers are good enough to optimise this better than the devs could themselves.
You see that the CPU and both GPUs in that slide have direct access to their local memory pool. In the sample on the right you have two bits of information, one stored in the CPUs memory pool and one stored in GPU1s memory pool, if the CPU wants what it stored in GPU1s memory pool it has to access it via the PCIe bus. Same for GPU0 if it wants to access what is stored in the CPUs or GPU1s memory pool. It just makes development easier as you do not have to manage where your data is, it is done for you but any cross memory requests still go via PCIe and still incur the latency hit. Nvidia are obviously confident that their drivers are good enough to optimise this better than the devs could themselves. You see the part where it says it will be a large part of Fusion APUs, that would be the HSA portion of this technology. The FireStream GPGPU is the HPC side which is a totally different thing. For HPC think folding or bitcoin (as more widely known examples), you take a data set, dump it on the GPU and let it churn through it. It does not require a lot of back and forth communication with the CPU so the latency hit is worth it for the extra performance. Bottom line is that HSA on a physical UMA is going to be better than HSA on a discrete GPU with a virtual UMA because the overheads are massively reduced. If you want to argue with this point, the main point I am making (and others have made), then feel free but since AMD say the same thing I am saying then you would be disagreeing with the hardware manufacturer themselves, which is a sticky position to put yourself in. http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/. EDIT: And LOL at your second slide, WOW. It says exactly what others have been saying, the first step to HSA is to integrate the GPU and CPU on a single piece of silicone and use a unified memory architecture so the GPU and CPU can access the same pool of ram. Exactly what both console do and PCs with APUs do. It does no mention discrete GPUs at all.You are the one that brought up Nvidia to show that the PCIe latency was low and I am just showing that the example you gave was correct in a specific set of constraints and is not a general rule. I am fully aware it is different to the slide but I love that you do not quote the text from the article the slide is from. Here is the snippet that you are not disclosing. (Emphasis added)
[QUOTE="Bright Side of News"]The new GCN architecture brings numerous innovations to GPU architecture, out of which we see x86 virtual memory as perhaps one of the most important ones. While the GPU manufacturers have promised functional virtual memory for ages, this is the first time we're seeing a working implementation. This is not a marketing gimmick, IOMMU is a fully functional GPU feature, supporting page faults, over allocating and even accepting 64-bit x86 memory pointers for 100% compatibility with 64-bit CPUs. Virtual memory is going to be the large part of next-gen Fusion APUs (2013) and FireStream GPGPU cards (2012), and we can only commend the effort made in making this possible.btk2k2
1. You missed "FireStream GPGPU cards" after "Fusion APUs" (Emphasis added).
2. You attempted to mis-direct NVIDIA's example and blame it on PCIe.
3. You missed AMD's "Don't Move The Data" slide.
4. You missed HSA will be extended to discrete GPU i.e. fabricengine example is just a test for this concept and AMD's "Don't Move The Data" slide. It needs to be in beta in 2013 not in 2014. Your time schedule is a joke.
The copy process can be avoid (with memory locality), but to scale the compute power, UMA is not enough.
EDIT2: To reply to your edits. RTFA. Anandtech state that it just moves the memory management from the developers to the drivers. It still happens because for the discrete GPU to have the data in its local registers it has to get it from some where. If it is in the main memory pool then it needs to copy it over PCIe bus. This is unavoidable because it is the physical reality of how it works. Just because the dev can see it as one pool of memory to make development easier does not mean that this is not going on in the background. Unless you think that Cuda 4 is made of magic pixie dust that enables a GPU to work on a data set that is physically stored in the main memory pool (so not the GPUs local memory pool) without transferring it over to its local registers in some way. EDIT3: Final Edit. Just look at the slide that is in the article, I will try to link it for you
You see that the CPU and both GPUs in that slide have direct access to their local memory pool. In the sample on the right you have two bits of information, one stored in the CPUs memory pool and one stored in GPU1s memory pool, if the CPU wants what it stored in GPU1s memory pool it has to access it via the PCIe bus. Same for GPU0 if it wants to access what is stored in the CPUs or GPU1s memory pool. It just makes development easier as you do not have to manage where your data is, it is done for you but any cross memory requests still go via PCIe and still incur the latency hit. Nvidia are obviously confident that their drivers are good enough to optimise this better than the devs could themselves.
btk2k2
My point with CUDA 4.0 is for dispatch overheads.
Both NUMA and UMA has thier place.
That is also before optimization and taking the unified fast ram into account
You would need more than 6 TFs to match games later in PS4 life
You see the part where it says it will be a large part of Fusion APUs, that would be the HSA portion of this technology. The FireStream GPGPU is the HPC side which is a totally different thing. For HPC think folding or bitcoin (as more widely known examples), you take a data set, dump it on the GPU and let it churn through it. It does not require a lot of back and forth communication with the CPU so the latency hit is worth it for the extra performance. Bottom line is that HSA on a physical UMA is going to be better than HSA on a discrete GPU with a virtual UMA because the overheads are massively reduced. If you want to argue with this point, the main point I am making (and others have made), then feel free but since AMD say the same thing I am saying then you would be disagreeing with the hardware manufacturer themselves, which is a sticky position to put yourself in. http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/. EDIT: And LOL at your second slide, WOW. It says exactly what others have been saying, the first step to HSA is to integrate the GPU and CPU on a single piece of silicone and use a unified memory architecture so the GPU and CPU can access the same pool of ram. Exactly what both console do and PCs with APUs do. It does no mention discrete GPUs at all.[QUOTE="btk2k2"]
You are the one that brought up Nvidia to show that the PCIe latency was low and I am just showing that the example you gave was correct in a specific set of constraints and is not a general rule. I am fully aware it is different to the slide but I love that you do not quote the text from the article the slide is from. Here is the snippet that you are not disclosing. (Emphasis added)
[QUOTE="Bright Side of News"]The new GCN architecture brings numerous innovations to GPU architecture, out of which we see x86 virtual memory as perhaps one of the most important ones. While the GPU manufacturers have promised functional virtual memory for ages, this is the first time we're seeing a working implementation. This is not a marketing gimmick, IOMMU is a fully functional GPU feature, supporting page faults, over allocating and even accepting 64-bit x86 memory pointers for 100% compatibility with 64-bit CPUs. Virtual memory is going to be the large part of next-gen Fusion APUs (2013) and FireStream GPGPU cards (2012), and we can only commend the effort made in making this possible.ronvalencia
1. You missed "FireStream GPGPU cards" after "Fusion APUs".
2. You attempted to mis-direct NVIDIA's example and blame it on PCIe.
3. You missed AMD's "Don't Move The Data".
4. You missed HSA will be extended to discrete GPU i.e. fabricengine example is just a test for this concept and AMD's "Don't Move The Data".
1) No I did not. I specifically said that the FireStream GPGPU is on the HPC side of this. If you are going to correct me then read what I write so you can actually get it right. 2) You said that DX is high latency so if you want to transfer over PCIe then do not use it. You than showed an example that used Nvidia's CUDA so I just showed that your example was true but limited in scope.3) That is from the software implementation side, the developer does not have to manage it as it is done by the driver. It is impossible for a GPU to work on something if it does not have it stored in its local registers/cache. The bulk of the data can be stored in a different memory pool but it still needs to move it across the PCIe bus for the GPU to actually manipulate it. It does not stay in the local memory of course but it still needs to move across.
4) In the examples with small models it was faster on the CPU because of the overhead. It is a shame they did not test the dGPU and the APU to see if the scenarios where the CPU was faster would have been the same on the APU. That would have been interesting. I notice you did not argue with my main point which is that HSA on an APU is going to be more efficient than HSA on a dGPU due to lower overheads. I am not saying that HSA on dGPU is impossible or worthless, it is just worse than an APU with a similar spec GPU due to overhead.PC is getting AMD HSA enabled Frostbite 3.0 and Unity3D.That is also before optimization and taking the unified fast ram into account
You would need more than 6 TFs to match games later in PS4 life
loosingENDS
Please Log In to post.
Log in to comment