[QUOTE="ronvalencia"]
I didn't imply anything. My post includes information on CU's max compute processing memory bandwidth from L1 cache and L2 cache I/O.
For X1's GCN, L1 bandwidth has 64 byte per cycle per CU = 50.8425 GB/s x 12 CUs = 610.11 GB/s.
One should look for any bottlenecks and seek the reasons on why it doesn't use extra memory bandwidth.
I have shown you why 7770/7790 @ 800 Mhz would gimp any memory faster than ~96 GB/s. AMD would need to redesign 7770/7790's crossbar/memory controller/L2 cache stack for faster memory based on GDDR6. For the X1, it's easier to "copy-and-paste" from the Pitcairn's crossbar/L2 cache/memory controller designs.
7770/7790 has a massive crossbar/L2 cache I/O bottleneck that gimps higher memory bandwidth e.g. not ready for GDDR6.
Reference http://www.behardware.com/articles/848-4/amd-radeon-hd-7970-crossfirex-review-28nm-and-gcn.html
------------------------
NVIDIA">http://www.behardware.com/articles/848-4/amd-radeon-hd-7970-crossfirex-review-28nm-and-gcn.html">http://www.behardware.com/articles/848-4/amd-radeon-hd-7970-crossfirex-review-28nm-and-gcn.html
------------------------
NVIDIA Kelper is different fish when it comes to handling it's compute workloads.
Entry level GK104 (e.g 660 TI) is another class of GPU above AMD Pitcairn i.e. it needs AMD Tahiti LE to battle NV 660 Ti.
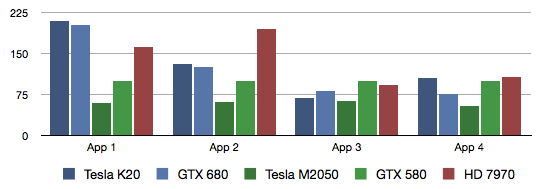
K20 vs 7970 vs GTX680 vs M2050 vs GTX580 from http://wili.cc/blog/gpgpu-faceoff.html
K20">http://wili.cc/blog/gpgpu-faceoff.html">http://wili.cc/blog/gpgpu-faceoff.html
K20 = GK110
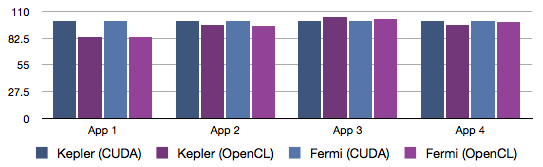
There's very difference between NVIDIA's OpenCL and CUDA.
App 1. Digital Hydraulics code is all about basic floating point arithmetics, both algebraic and transcendental. No dynamic branching, very little memory traffic.
App 2. Ambient Occlusion code is a very mixed load of floating point and integer arithmetics, dynamic branching, texture sampling and memory access. Despite the memory traffic, this is a very compute intensive kernel.
App 3. Running Sum code, in contrast to the above, is memory intensive. It shuffles data through at a high rate, not doing much calculations on it. It relies heavily on the on-chip L1 cache, though, so it's not a raw memory bandwidth test.
App 4. Geometry Sampling code is texture sampling intensive. It sweeps through geometry data in "waves", and stresses samplers, texture caches, and memory equally. It also has a high register usage and thus low occupancy.
Minimise App 2 type workloads, Kepler's would perform fine.
tormentos
W5000/7850-768 @ 853hz, L2 cache I/O bandwidth: 256 bytes x 853Mhz = 203.37 GB/s. ESRAM was design for Pitcairn level I/O.
Yeah you did..
In fact a W5000 768 @853 mhz = and over clock GPU.
The speed of the W5000 is 825mhz to 853mhz would mean is slightly over clocked,so how many over clocked GPU have you see on consoles.?
ESRAM wasn't design for Pitcairn ESRAM is a damn band aid use by MS to help those starved components because MS chose DDR3,if the xbox one used GDDR5 even 102Gbs the xbox now would not even had ESRAM.
So for you a gimped 7790 will perform better than a 7950 if you give it more bandiwdth you are a joke,i proved my point 100GB/s less yet the performance is the same.
I didn't imply anything.
7950 @ 800Mhz, L2 cache I/O bandwidth: L2 cache I/O bandwidth: 364 bytes per cycle x 800 Mhz = 300 GB/s.
7950 @ 950Mhz (fastest out-of-the-box edition), L2 cache I/O bandwidth: L2 cache I/O bandwidth: 364 bytes per cycle x 950 Mhz = ~337.7GB/s.
X1's L2 cache I/O bandwidth is not even close to 7950 @800Mhz. Your wrong again.
AMD.com's W5000 @ 1.3 TFLOPS would need about 853Mhz clock speed. There are W5000s with slightly clock speeds. AMD doesn't ultimately dictate the final GPU clock speed i.e. that's AIB (Add In Board)'s or OEM's decisions.
10Mhz overclock is minor i.e. I overclocked my 7950-900mhz to 950Mhz without any voltage increase. MS overclocked X1's GPU by 53 Mhz. Your issue on this subject is just noise i.e. it's a "who cares" episode.
-------
X1 has GCN's 256bit memory controllers and related L2 cache I/O bandwidth i.e. 203.37 GB/s which can cover 133 GB/s (via ESRAM) alpha blend was the effective bandwidth for the prototype X1.
A 7770 or 7790's L2 cache I/O bandwidth would not cover 133 GB/s (via ESRAM) alpha blend. This is why the prototype-7850 with 768 stream processors @ 860Mhz is a closer fit to the X1's GCN.
Giving 7790 more bandwidth is nearly pointless since it's 128byte per cycle L2 cache I/O would gimp it. Each memory controller, has 64byte per cycle L2 cache bandwidth. The joke is you since you haven't identified the bottleneck in the 7790.
Also, 7950 has substantially larger internal SRAM storage than 7790.




 .
.




Log in to comment